
Na blogu Dana Krásného jsem nedávno četl jeho úvahu nad tím, proč Jiří Drahoš kvůli Facebooku nevyhraje volby a zaujaly mě v ní dvě věci. Jednak to, že se v ní vyskytuje slovo „odprostěte se“ (berte tuhle poznámku prosím jako snahu o humory a ne jako výzvu k náletu grammar nazis na moje příspěvky, protože z toho bych nikdy nemohl vyjít dobře) a potom jeho konstatování, že vystupování Jiřího Drahoše na Facebooku by se dalo shrnout větou „nudný pán na něm dělá nudné věci„. S tím se dá těžko jakkoliv polemizovat, ale faktem zůstává, že i přes to sbírají jeho nudné věci pravidelně stovky či tisíce lajků.
Začalo mě tedy zajímat, kdo jsou lidé, kteří Jiřímu Drahošovi na Facebooku „fandí“. Ano, tušíte správně, vedlo mě to k jedné z těch analýz, ve které po spoustě práce na konci vyjde to, co jste podvědomě věděli už na jejím začátku. Ne, nebudu hodnotit, jestli ty výsledky znamenají, že měl Dan pravdu a Drahoš příští rok na známkách nebude. Čistě na základě téhle analýzy to ze spousty důvodů ani nejde. Dovolím si ale drze tvrdit, že i tak měla smysl a zejména pokud bych ji zopakoval i pro další kandidáty, mohly by z toho vylézt zajímavé profily jejich podporovatelů a jejich porovnání. Pokud by vám něco takového dávalo smysl, budu rád, když dáte vědět v komentářích nebo kdekoliv jinde.
Co mají rádi ti, co mají rádi Drahoše?
Celá analýza vychází z toho, že hledáte stránky, které jsou nejvíc oblíbené mezi lidmi, kteří lajkují posty na konkrétní stránce (v tomto případě na stránce Jiřího Drahoše). Poprvé jsem na tento přístup narazil u Jana Schmida, který jej popsal v článku Analýza lajků fanoušků – indulona jako „folková nostalgie v obýváku“. Nedávno jej využil například Josef Šlerka ve svém příspěvku Slušní lidé na Facebooku, ve kterém mimochodem velmi přehledně popisuje její základní principy.
Prvním krokem bylo vytvoření datasetu, který obsahoval ID všech uživatelů, kteří jakkoliv reagovali s některým ze 100 posledních postů na stránce (ke dni 21.11.2017). Celkem šlo o více než 116 tisíc reakcí, z nichž přes 90 % byly klasické „lajky“. Ostatní typy reakcí jsem pro další analýzu ignoroval.
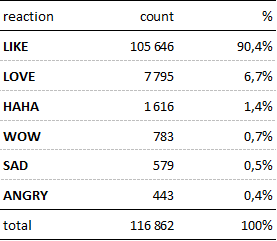
Rozložení lajků přes jednotlivé posty v čase vypadalo následujícím způsobem – každý bod reprezentuje jeden post a jeho výška počet lajků, které mu byly uděleny k 21.11.2017:
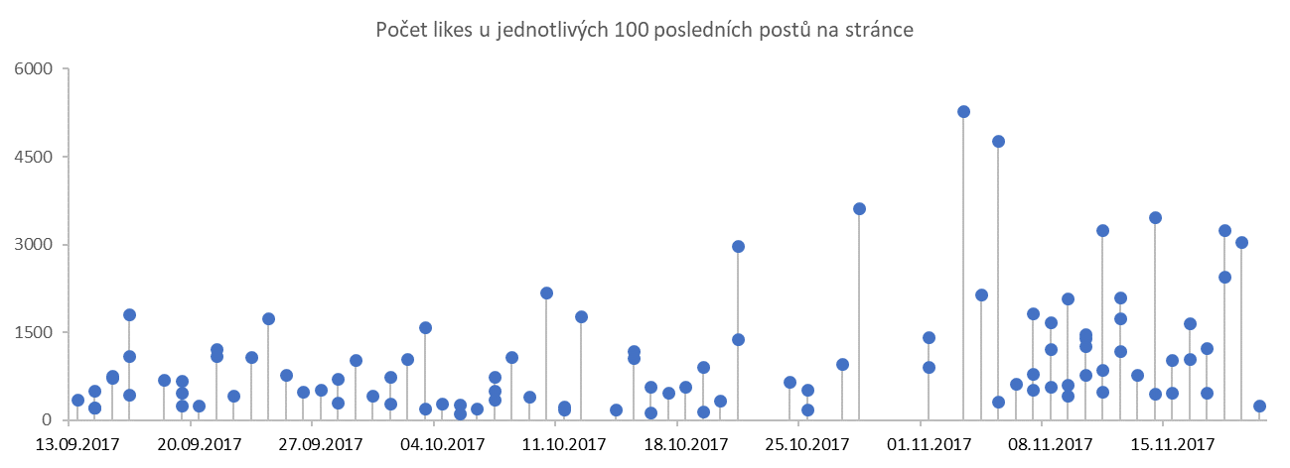
I když to původně nebyl můj záměr, zkusil jsem spočítat průměrný počet lajků pro posty v jednotlivých dnech týdne. Zjistil jsem, že ačkoliv pan Drahoš (nebo jeho tým) publikuje přibližně stejné počty postů bez ohledu na to, o který den v týdnu se jedná, z hlediska jejich lajkování jsou výrazně úspěšnější ty víkendové. Nerad bych z toho dělal nějaký závěr, protože si nejsem jistý tím, jestli se nejedná o nějaký obecný vzorec chování na Facebooku (o víkendu se lajkuje víc než v pracovní dny) a rád si nechám poradit, pokud to někdo tušíte. Nicméně na sledované stránce získal každý průměrný víkendový post více než dvojnásobek lajků, které získávaly průměrné posty publikované v pracovní dny (viz graf dole).
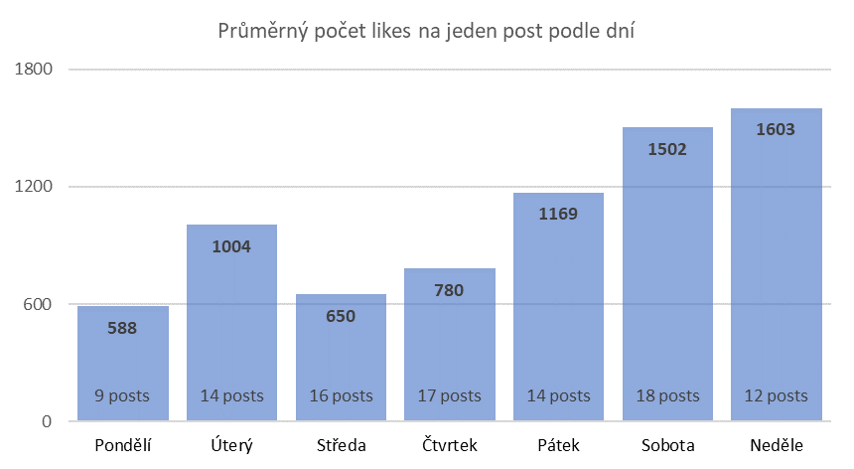
Velikosti oblíbených stránek a afinita
Druhým krokem byl výběr pěti set nejaktivnějších uživatelů (těch, kteří olajkovali nejvíce postů) a následné stažení všech stránek, kterým dali tito uživatelé lajk. Zatímco až do teď bylo možné si vystačit s API Facebooku, krok dva už Facebook žádným standardním způsobem neumožňuje provést, takže bylo nutné napsat vlastní skript, který procházel veřejné profily každého z pěti set vybraných uživatelů a „četl“ seznam jejich oblíbených stránek. Takto se mi podařilo získat informace o 311 uživatelích s veřejným profilem, kteří olajkovali přes 21 tisíc různých Facebookových stránek, se kterými jsem pracoval dále. U stránek, které lajkovalo alespoň 10 uživatelů z mého vzorku jsem potom (již opět přes API) získal informaci o celkovém počtu jejich fanoušků, která byla nezbytná pro výpočet jejich afinit.
Princip výpočtu afinity popisuje Josef Šlerka v již zmíněném článku, ale i tak ve zkratce – afinita vyjadřuje, jak moc je stránka „typická“ pro sledovaný vzorek uživatelů. To, že konkrétní stránku olajkovalo např. 30 % uživatelů ve sledovaném vzorku, totiž ještě není nijak směrodatná informace, pokud nevíte, jak je ta stránka oblíbená v celé české Facebookové populaci. Za předpokladu, že danou stránku lajkuje 50 % všech českých Facebookových uživatelů, je její afinita 0,3/0,5 = 0,6 a pro sledované uživatele je tedy spíše netypické, že by danou stránku lajkovali (i když se na ní shoduje 30 % vzorku). Naopak čím vyšší je afinita nad 1, tím je pro sledovaný vzorek uživatelů „typičtější“. Dvacet nejafinitnějších stránek si můžete prohlédnout v grafu dole (modrá barva reprezentuje afinitu a oranžová barva vyjadřuje kolik procent z 311 sledovaných uživatelů dalo lajk právě této stránce). Kompletní seznam stránek s jejich afinitami si můžete stáhnout ve formátu csv.
Logicky nejafinitnějšími stránkami jsou ty, které podporují prezidentskou kandidaturu pana Drahoše. Zajímavé to začíná být až za nimi. Nejtypičtějšími stránkami po fanoušky pana Drahoše jsou stránky osobností české politické scény, jako například Jakuba Hrušky – zastupitele na Praze 6 za TOP 09, poslance za TOP 09 Vlastimila Válka, z hnutí ANO nedávno vystupivšího europoslance Pavla Teličky, diplomata Petra Koláře (který taktéž zvažoval kandidaturu na prezidenta), toho relativně normálního Okamury – Hayata, místopředsedy TOP 09 Tomáše Czernina, nebo europoslance opět za TOP 09 Jaromíra Štětinu.
Najdete mezi nimi i třeba stránku podporující utopický sen některých „lidí z Prahy“ – Miroslav Kalousek premiérem, iniciativu Kroužkujeme osobnosti nebo Hledáme prezidenta – Kroměřížská výzva, případně stránku, která mluví sama za sebe – Jsem pravdoláskař a jsem na to hrdý.
Pro úplnost uvádím i seznam dvaceti stránek s nejvyšší penetrací v daném vzorku (lajkoval je největší počet z 311 sledovaných uživatelů, bez ohledu na afinitu):
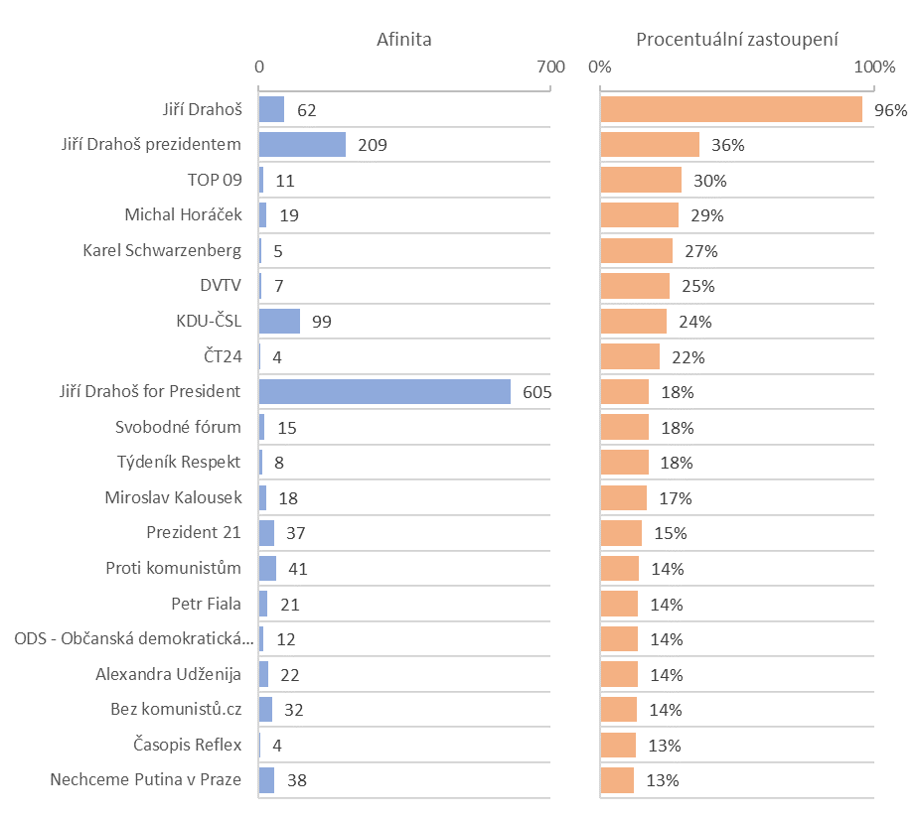
Ačkoliv jsou afinity těchto „nejoblíbenějších“ stránek relativně nízké, i tak jsou všechny vyšší než jedna a nelze je tedy ignorovat. Při řazení podle „popularity“ se do popředí proderou stránky politických stran, nově sdružených do tzv. „demokratického bloku“ – TOP 09, KDU-ČSL a ODS, stránka dalšího prezidentského kandidáta Michala Horáčka a minulého protikandidáta Miloše Zemana – Karla Schwarzenberga, dále několik protikomunistických či protiruských stránek a facebookové stránky médií jako DVTV, ČT24, Respekt nebo Reflex.
Radši Drahoš než Miloš
Bez ohledu na další psí kusy, které jsem s daty ještě zkoušel se profil fanoušků pana Drahoše dá celkem dobře sestavit už teď. V poslední prezidentské volbě byli spíš pro Karla než pro Miloše, volili by spíš TOPku než ANO, a to ještě spíš konkrétní lidi než nějakou „masu“, sledují spíše DVTV než Parlamentní listy, spíš než Rusko je láká západ, a spíš než na vesnici je najdete v Krymský, kde popíjejí fair-trade kafe a hrajou na ukulele.
Ok, tady jsem se už nechal trochu unést… Berte prosím veškeré závěry s rezervou, která by měla být dána vědomím, že jde pořád jen o analýzu 311 nejaktivnější uživatelů na 100 posledních postech, ne o žádnou sociologickou studii. I tak si ale myslím, že jakýsi virtuální obraz typického Drahošova fanouška se z ní vyvodit dá.
Shlukování
Tak trochu nad rámec svého původního cíle jsem se nechal inspirovat již několikrát zmiňovaným článkem Josefa Šlerky a pokusil se o trochu hlubší vhled do oblíbených stránek fanoušků Jiřího Drahoše. Vybral jsem z nich jen ty, které olajkovalo alespoň deset procent mnou sledovaného vzorku uživatelů a jejich afinita je zároveň vyšší než deset. Na tyto stránky jsem poté použil metodu hierarchického shlukování, která jednotlivé stránky podle míry jejich podobnosti postupně shlukuje do větších a větších clusterů. Výsledek potom vypadá následovně:
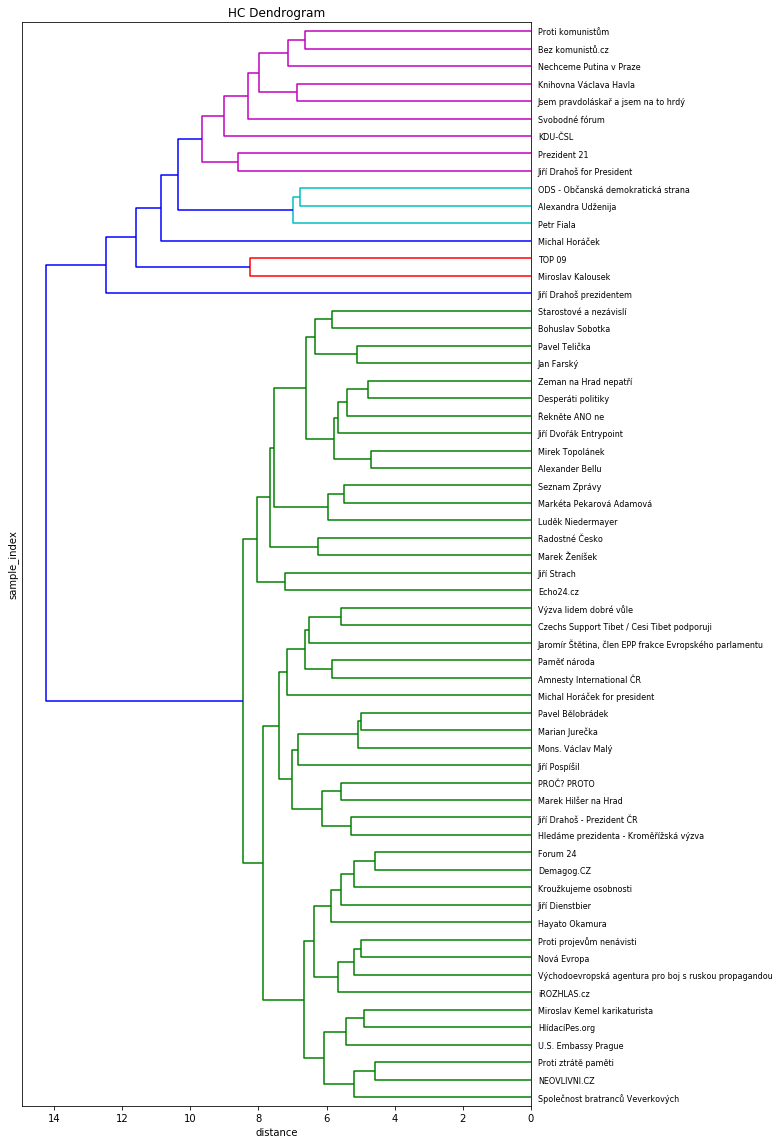
Celkem snadno lze identifikovat růžovofialový shluk stránek namířených proti komunismu a ruskému vlivu, „příslušníků“ pravdoláskařů, Knihovny Václava Havla, Svobodného fóra a KDU-ČSL.
Vzhledem k tomu, že na nejvyšší úrovni vytvořil algoritmus vlastně jen dva clustery – jeden zelený a jeden „barevný“, podíval jsem se ještě detailněji na velmi početný zelený shluk. V něm lze dále rozpoznat některé dílčí skupiny spřízněných stránek, které mají společné téma. Například žlutý shluk stránek Kroužkujeme osobnosti, Hlídací pes, Fórum24, Demagog.cz, iRozhlas, Proti ztrátě paměti a Neovlivni.cz, který by se snad dal pojmenovat jako stránky spojené s nezávislým zpravodajstvím, objektivní žurnalistikou a svobodnému přístupu k informacím. Asi. Problémem téhle metody (shlukování obecně) je, že vám sice setřídí stránky, které z hlediska určitých kritérií patří k sobě, ale neřekne vám, co je tím pojícím tématem. Pokud by měl někdo ambice pokusit se interpretovat jednotlivé shluky detailněji, stačí dát vědět a rád poskytnu komplet dataset k dalšímu zkoumání.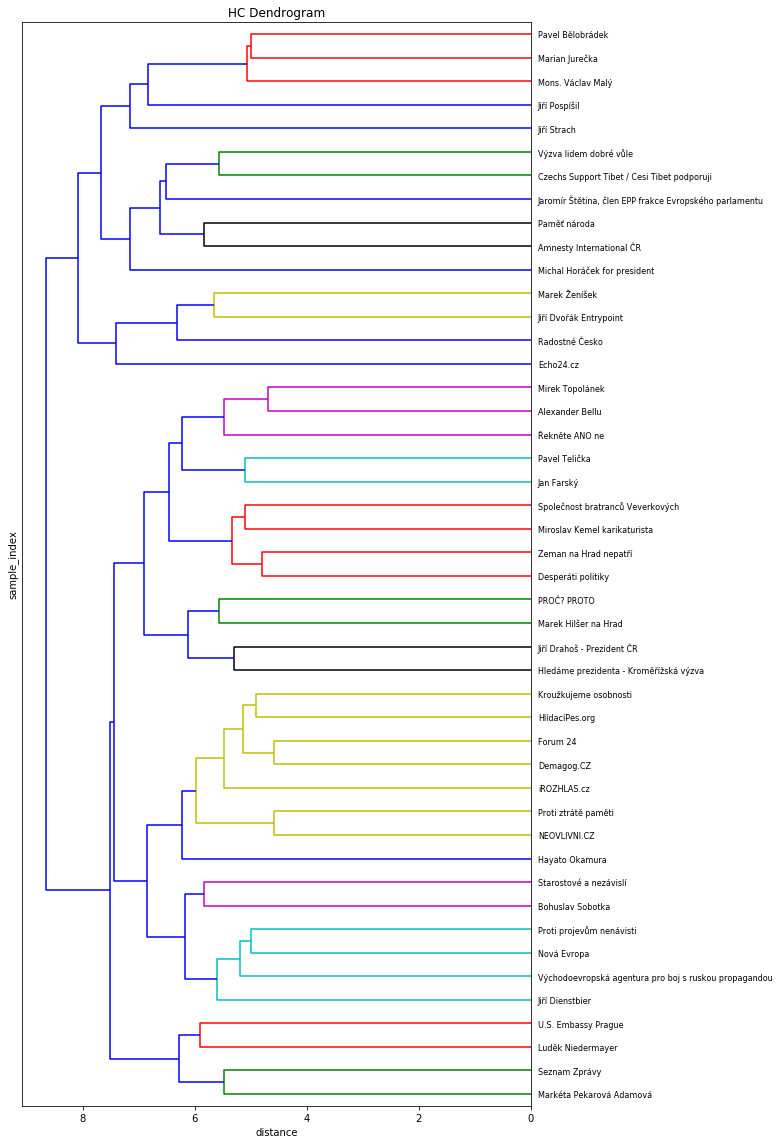
Co dál?
Jak jsem předestřel na začátku, nic z toho, co jste si přečetli (a pokud jste dočetli až sem, tak respekt), nepomůže žádným způsobem odhadnout výsledek pana Drahoše v prezidentské volbě. Snad by to ale mohlo alespoň trochu pomoci při snaze pochopit to, z jakých skupin se pravděpodobně budou rekrutovat jeho voliči. Pokud by o to byl zájem (a dost volného času) pokusím se zpracovat podobný profil i pro další kandidáty. Zajímavý by mohl být také pohled na to, kteří kandidáti k sobě mají nejblíž z hlediska překryvu uživatelů Facebooku, kteří lajkují jejich posty. Pokud by někoho napadl jakýkoliv jiný zajímavý způsob využití tohoto typu dat, budu rád za tip.
Můžete prosím popsat s jakými nástroji jsou uvedené analýzy dělány – stažení těch dat z FB přes API a následné zpracování do podoby výsledků?
Je na to potřeba programátorská znalost nebo se dají ty skripty někde stáhnout a použít univerzálně?
Datům zatím nehovím, ale tohle mě tedy extrémně zajímá.
Díky
Honza
Popsat nástroje určitě můžu. Obecně řečeno těch způsobů, kterými se dá k obdobnému výsledku dospět je určitě víc a já si zkrátka našel jeden z nich. V mém konkrétním případě je nějaká naprosto základní znalost programovacího jazyka nutná (ale vážně jen základní, protože sám taky žádnou hlubší nemám :)).
K těm nástrojům – největší část práce odvedly skripty napsané v jazyce Python a to konkrétně s využitím knihoven jako requests, mechanize nebo beautifulsoup, ta shlukovací část potom ve scipy.cluster.hierarchy. Konkrétní skripty, které jsem si k tomu napsal se teď stáhnout nikde nedají, ale plánuji je publikovat někde na githubu, takže potom to možné bude. Nicméně můžete si je napsat i sám (s tou zmiňovanou základní znalostí programovacího jazyka), protože i já jsem vlastně postupoval tak, že jsem využíval různé části již hotových řešení, které někdo publikoval na internetu (třeba tady http://simplebeautifuldata.com/2014/09/09/harvesting-facebook-posts-and-comments-with-python-part-1/).
Budu se snažit dát v nejbližší době dohromady nějaký konkrétnější popis toho samotného postupu i s kódem a dám vám potom vědět.