
Protože jsem až teprve nedávno objevil bezednou studnici zábavy jménem AWS Rekognition a protože je tahle studnice ještě navíc zdarma, hledal jsem příležitost, jak si ji vyzkoušet. No a na čem jiném zkoušet computer vision službu, než na jiné službě, které se v poslední době prakticky stala synonymem pro „obrázky“ – Instagramu. Podle Amazonu jde navíc o produkt, který, cituji, „requires no … expertise at all„, což je přesně ta úroveň expertízy, kterou mám já.
Jedna ze služeb, které AWS nabízí, je již zmíněná identifikace objektů, scén a obecně kontextu v obrázcích, což mě přivedlo na myšlenku, zda by se nedaly vytvořit skupiny instagramových profilů, které postují podobně laděné fotky (z hlediska toho, co na fotkách je) a vytvořit tak segmenty profilů orientovaných na sport, módu, jídlo, soft porno nebo fotky srandovně oblečených čivav nebo jiný typicky instagramový obsah. Čistě pro info – další text neobsahuje žádné soft ani jiné porno, takže pokud pokračujete ve čtení kvůli té zmínce o něm, tak můžete v klidu přestat. Ale byla by to škoda. Pokud Vás zajímá, zda z toho něco bylo, ale je Vám jedno, jak jsem se k tomu dostal, můžete skočit rovnou na konec. Ale taky by to byla škoda…
Kdo je kdo na českém Instagramu
Jako první bylo potřeba sehnat seznam instagramových profilů, které by stálo za to výše popsaným způsobem vyhodnotit. Pomohl mi v tom článek Nejsledovanější česko-slovenští instagrameři. Teď už se můžete podívat, co sledují vaše děti na Flowee.cz, ze kterého jsem převzal seznam sto padesáti, údajně nejsledovanějších českých instagrammerů. Článek je z poloviny loňského roku, takže výčet nemusí být úplně aktuální, ale vzhledem k tomu, že má znalost české insta scény je zhruba na úrovni mé schopnosti hrát na elektrofonický vál na nudle, jsem jej přejal tak, jak jsem ho našel.
Instagram semi-API
Vzhledem k tomu, že Instagram neposkytuje veřejnou API, která by umožňovala strojově procházet jednotlivé profily a získávat z nich zveřejněné fotky, využil jsem možnost přidat za adresu uživatelského profilu parametr ?__a=1. Ten dovolí získat strukturovaná data o posledních dvanácti postech daného uživatele ve formátu .json. Výsledný formát dat pro posledních dvanáct postů Leoše Mareše si můžete prohlédnout po zadání tohoto odkazu do prohlížeče – https://www.instagram.com/leosmares/?__a=1.
Druhá možnost, která by navíc dovolila sebrat informace o více než jen dvanácti posledních postech je samozřejmě web scraping, ale vzhledem k mé lenosti a faktu, že tenhle přístup není tak úplně „fér“, rozhodl jsem se, že si vystačím s dvanácti fotkami pro každý ze sto padesáti profilů. Jejich URLs jsem získal s pomocí dole uvedeného Python scriptu s knihovnou requests.
import requests
import pandas as pd
from datetime import datetime as dt
# seznam 150 CZ instagrammers - https://www.flowee.cz/ditevsiti/bezpeci/6822-instagram-influenceri
profiles = ['daviddobrik', 'petrcech', 'petosagan', 'luciajavorcekova', 'gogomantv', 'silviemahdal_art', 'leosmares',
'zuzkalight', 'karolinakurkova', 'jirkakral', 'bennycristo', 'lucypug', 'shopaholicnicol', 'denisemilaniofficial',
'anasulcova', 'kovy_gameballcz', 'expl0ited_', 'ment97', 'martin_carev', 'fashioninmysoul', 'dararolins_vermi',
'rytmusking', 'queen.plackova', 'martinahornakova', 'vladavideos', 'petra.kvitova', 'fallenkaa', 'domicibulkova',
'taraspovoroznyk', 'majkspirit', 'tresnickova', 'terihodanova', 'ewa_farna93', 'petrlexa', 'kazma_kazmitch',
'erikmeldik', 'alenaseredova', 'beha_nguyen', 'stejkstudio', 'pedrosgame', 'makhmud_muradov', 'stibrovicnikolka',
'gejmr', 'tomasberdych', 'simonakrainova', 'fattypilloww', 'karolinapliskova', 'menameselassie', 'svetpodlekatky',
'jakub.house', 'bagarovamonika', 'jasmina_alagic', 'nelaslovakova', 'mikolasjosef', 'bara_vot',
'sharlotaofficial', 'veronikaarichtev', 'monikamaresova', 'andy_coconut', 'natalie.tolarova', 'andreaveresovaofficial',
'annakaderavkova', 'mamadomisha', 'recepty', 'sajfa', 'nejfake', 'sweetiemarket', 'luboskulisek', 'getthelouk', 'egoemo',
'separ_dms', 'dezertkalimusic', 'simonahegerova', 'wedrylp', 'minaisbest', 'gabgab_gabi', 'stanik29', 'jeera',
'anniecamell', 'notsofunnyany', 'atishows', 'iamcarriekirsten', 'makyna016', 'petralovelyhair', 'timeatrajtelova',
'dominikamyslivcova', 'viralbrothers', 'nikolsvantnerova_official', 'tmbkofficial', 'lela_ceterova_official', 'chefkamu',
'johnymachette', 'martin_creep', 'artixik', 'tinaslovakia', 'luciebila', 'marta.jandova', 'nicole_e', 'pavolhabera',
'agatahanychova', 'davidgransky', 'jitkanovackova', 'a.n.d.u.l.a', 'adamkajumi', 'lucie_ehr', 'naty_hrychova',
'daniela_pestova', 'alkan_hraje', 'veronicabiasiol', 'terezaa.maskova', 'pjay', 'pavelcallta', 'acupofstyle',
'pnemcova', 'lea_ofc', 'tvtwixx', 'terysa18', 'kubickovakristyna', 'veghattila', 'eliskabuckova_official',
'karolinamalisova', 'evabureshsalvatore', 'aless_capparelli', 'martin37skrtel', 'denny_polakova', 'maripracharova',
'karolinachomistek', 'anna.puric', 'justdejvit', 'fizistyle', 'nikolmoravcova', 'attackkk_', 'mama.lifestyle',
'petan_esterka', 'lukefry', 'the.sima_', '_nachty_', 'flyguncz', 'davidvorak', 'andrejsomberg','ondymikula',
'anna_hamannova', 'siirotenko', 'patulmichalkova', 'livemadlife']
lst_p = []
lst_m = []
timestamp = dt.now().strftime("%d/%m/%Y, %H:%M:%S")
print(timestamp)
for i, p in enumerate(profiles, start=1):
print('Scrapping profile no.: {0} - {1}'.format(i, p))
url = 'https://www.instagram.com/{}/?__a=1'.format(p)
response = requests.get(url)
js = response.json()
p_id = js['graphql']['user']['id']
p_username = js['graphql']['user']['username']
p_followers = js['graphql']['user']['edge_followed_by']['count']
p_full_name = js['graphql']['user']['full_name']
p_is_private = js['graphql']['user']['is_private']
p_is_verified = js['graphql']['user']['is_verified']
p_is_ba = js['graphql']['user']['is_business_account']
p_bc_name = js['graphql']['user']['business_category_name']
tmp_lst_p = [p_id, p_username, p_full_name, p_is_private, p_is_verified, p_is_ba, p_bc_name, p_followers, timestamp]
lst_p.append(tmp_lst_p)
for m in js['graphql']['user']['edge_owner_to_timeline_media']['edges']:
m_id = m['node']['id']
m_url = m['node']['display_url']
m_like = m['node']['edge_liked_by']['count']
m_comment = m['node']['edge_media_to_comment']['count']
m_is_video = m['node']['is_video']
if len(m['node']['edge_media_to_caption']['edges']) == 0:
m_text = 'None'
else:
m_text = m['node']['edge_media_to_caption']['edges'][0]['node']['text']
if 'accessibility_caption' in m['node']:
m_acc_caption = m['node']['accessibility_caption']
else:
m_acc_caption = 'None'
if m['node']['location']:
m_location = m['node']['location']['name']
else:
m_location = 'None'
tmp_lst_m = [p_id, m_id, m_is_video, m_location, m_acc_caption, m_text, m_like, m_comment, m_url, timestamp]
lst_m.append(tmp_lst_m)
df_p = pd.DataFrame(lst_p, columns=['p_id', 'p_username', 'p_full_name', 'p_is_private', 'p_is_verified', 'p_is_ba', 'p_bc_name', 'p_followers', 'timestamp'])
df_m = pd.DataFrame(lst_m, columns=['p_id', 'm_id', 'm_is_video', 'm_location', 'm_acc_caption', 'm_text', 'm_like', 'm_comment', 'm_url', 'timestamp'])
df_p.to_csv('profiles.csv')
df_m.to_csv('media.csv')
V této fázi vypadlo asi pět profilů, které nebyly veřejné nebo již neexistovaly. V případě, že post nebyl fotka ale video, získal jsem jeho náhledový obrázek a dále s ním pracoval jako s fotkou. Výsledkem jsou csv s daty o profilech a jednotlivých postech (včetně počtů likes, comments a dalších atributů). Všechny fotky byly staženy dne 2. února 2020. U všech profilů tedy dále pracuji s posledními dvanácti fotkami, které byly k dispozici k tomuto dni.
Jak to vidí AWS
Dalším krokem bylo nechat všech cca 1800 obrázků zpracovat algoritmem na detekci objektů a scén v AWS Rekognition. V rámci neplacené Free Tier licence tahle služba dovoluje zpracovat až pět tisíc obrázků měsíčně po dobu jednoho roku, takže prostoru na hraní je k dispozici až až. Pro názornou představu toho, jak zpracovaný obrázek vypadá se můžete podívat na screenshot dole. K vyhodnocení jsem zadal post z instagramového účtu @petrcech.
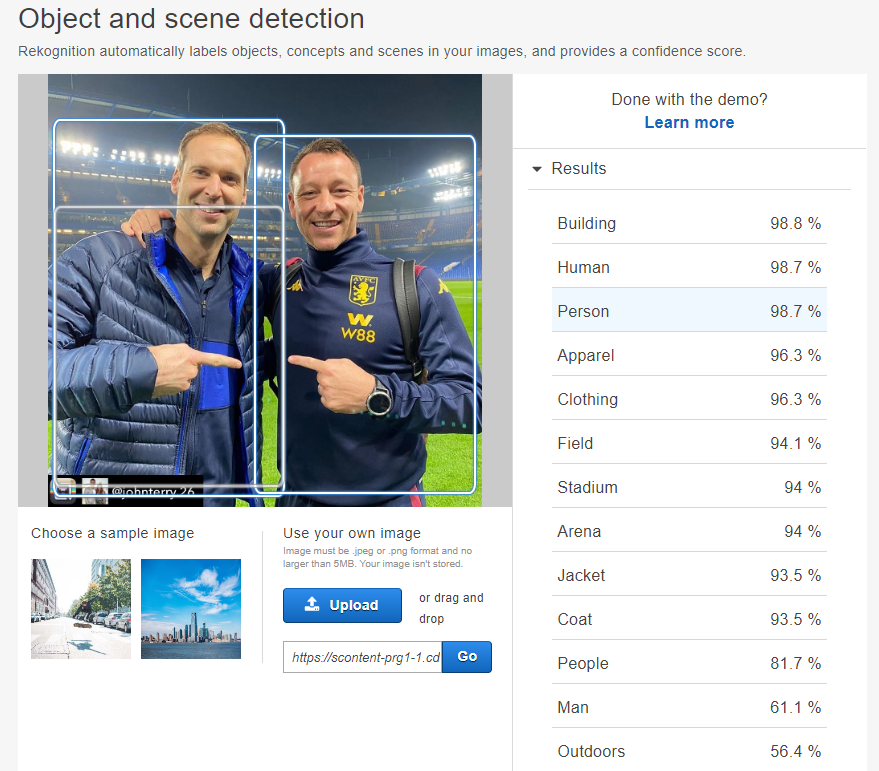
Jak můžete vidět vpravo, podle AWS jsou na obrázku s pravděpodobností přes 90 % osoby, budova, oblečení, hřiště, stadion nebo bunda. Což velice věrně odpovídá skutečnosti. Takovéto vyhodnocení si může zkusit každý přímo v prohlížeči pomocí demo módu, který je k dispozici po přihlášení do AWS konzole a nevyžaduje žádný kód. S využitím Python knihovny boto3 přímo od AWS je možné „posílat“ fotky k vyhodnocení strojově (s drobnou úpravou je před tím ani nemusíte uploadovat na S3 ale poslat je přímo z jejich URL). AWS potom jako výsledek vrátí detekované objekty a scény spolu s hodnotami pravděpodobnosti ve formátu .json. Všech cca 1800 fotek lze potom nechat strojově vyhodnotit pomocí následujícího skriptu. Výsledkem je dataset s příslušnými labels ke všem obrázkům.
import boto3
import requests
import pandas as pd
df_m = pd.read_csv('media.csv', index_col=0)
client = boto3.client('rekognition',
'eu-west-1',
aws_access_key_id='your-aws-access-key-id',
aws_secret_access_key='your-aws-secret-access-key')
lst_l = []
for i, m in df_m.iterrows():
if (i+1) % 50 == 0:
print('Labeling image no.: {}'.format(i+1))
m_id = m['m_id']
m_url = m['m_url']
ig_response = requests.get(m_url, stream=True)
img = ig_response.content
aws_response = client.detect_labels(Image={'Bytes': img})
for l in aws_response['Labels']:
l_name = l['Name']
l_confidence = l['Confidence']
l_parent = [x['Name'] for x in l['Parents']]
tmp_lst_l = [m_id, l_name, l_confidence, l_parent]
lst_l.append(tmp_lst_l)
df_l = pd.DataFrame(lst_l, columns=['m_id', 'l_name', 'l_confidence', 'l_parent'])
df_l.to_csv('labels.csv')
Protože mi ve výsledku nejde o hodnocení individuálních fotek, ale instagramových profilů, které je sdílely, spočítal jsem nakonec kolikrát se daný label objevuje na fotografiích sdílených daným uživatelem. Výsledkem je potom „tabulka“, kde v řádcích jsou jednotlivé instagramové účty, ve sloupcích jednotlivé detekované objekty z fotek a v buňkách počet, kolikrát byl daný objekt detekován ve vyhodnocovaném vzorku dvanácti fotek z daného profilu.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
from sklearn.decomposition import FactorAnalysis
from IPython.display import display
import cv2
import requests
sns.set_style('darkgrid')
df_p = pd.read_csv('profiles.csv', index_col=0, parse_dates=['timestamp'])
df_p.drop(['p_is_private', 'p_is_verified', 'p_is_ba', 'p_bc_name', 'timestamp'], axis=1, inplace=True)
df_m = pd.read_csv('media.csv', index_col=0, parse_dates=['timestamp'])
df_m.drop(['timestamp'], axis=1, inplace=True)
df_l = pd.read_csv('labels.csv', index_col=0)
df_l = df_l[df_l['l_confidence'] > 75]
display(df_p.sample(5))
display(df_m.sample(5))
display(df_l.sample(5))
df_pm = pd.merge(df_p, df_m[['p_id', 'm_id', 'm_is_video', 'm_like', 'm_comment', 'm_url']], on='p_id', how='inner')
df_pm.sample(5)
df_pm_agg = df_pm.groupby('p_username').agg({'p_followers':'mean', 'm_id':'count', 'm_is_video':'sum', 'm_like':['sum', 'mean'], 'm_comment':['sum', 'mean']})
df_pm_agg.columns = df_pm_agg.columns.map('_'.join)
df_pm_agg.columns = [x[2:] for x in df_pm_agg.columns]
df_pm_agg['like_per_foll'] = df_pm_agg['like_mean'] / df_pm_agg['followers_mean']
df_pm_agg['comment_per_foll'] = df_pm_agg['comment_mean'] / df_pm_agg['followers_mean']
display(df_pm_agg.sample(5))
df_l_agg = df_l.groupby('m_id')['l_name'].apply(list)
df_l_agg = pd.DataFrame(df_l_agg.apply(lambda row: {x:1 for x in row}).tolist(), index=df_l_agg.index).reset_index()
display(df_l_agg.sample(5))
df_ml = pd.merge(df_m, df_l_agg, on='m_id', how='inner')
display(df_ml.sample(5))
df_pml = pd.merge(df_p, df_ml, on='p_id', how='inner')
display(df_pml.sample(5))
df_pml_agg = df_pml.groupby('p_username').sum()
df_pml_agg = df_pml_agg.iloc[:,6:]
df_pml_agg.sort_index(axis=1, inplace=True)
display(df_pml_agg.sample(5))
Rozhodující faktor
Vzhledem k tomu, že unikátních labelů (objektů nebo scén), které se na obrázcích objevily, bylo dohromady skoro 800, nedává moc smysl pracovat s každým z nich jednotlivě. Zároveň dává jistý smysl myšlenka, že na obrázcích, které zachycují stejné nebo podobné scény (např. jídlo v restauraci, sportovní aktivity, selfies apod.) by se spolu měly objevovat podobné kombinace jednotlivých labels.
Přesně pro tento typ úloh se hodí faktorová analýza, která se snaží ve velkém počtu vstupních labels odhalit malý počet tzv. latentních proměnných, v našem případě řekněme „významů“ jednotlivých fotek. Počet „významů“ je potřeba dopředu zvolit a pro tento konkrétní případ jich je osm. Přehled výsledných faktorů, které dále slouží jako nové proměnné a objektů, které s nimi nejsilněji korelují je v následující tabulce. Názvy faktorů jsou výsledkem mé nepříliš bohaté představivosti a rozhodně je nelze brát jako jediné možné a správné. Kdokoliv jiný by pravděpodobně zvolil názvy jiné a jednotlivým faktorům by možná přisoudil i jiný význam.
| Faktor | Top 5 objektů korelujících s faktorem |
| cars-bikes | transportation, vehicle, machine, wheel, bicycle |
| posh-female | female, woman, girl, kid, child |
| urban | building, town, city, urban, architecture |
| holiday | plant, palm tree, arecaceae, tree, summer |
| posh-man | man, face, wall, brick, flare |
| casual | path, plant, pedestrian, downtown, restaurant |
| outdoor | motorcycle, outdoors, path, nature, mountain range |
| fashion-style | gown, robe, fashion, evening dress, apparel |
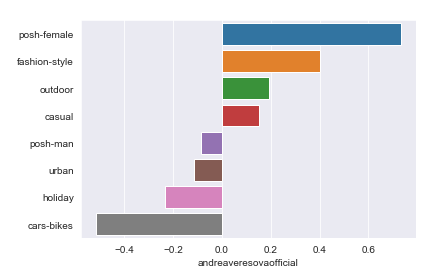
Jako zkoušku toho, zda význam přiřazený jednotlivým faktorům odpovídá, jsem zkusil tímto způsobem vyhodnotit vzorek fotek získaných z profilu @andreaveresovaofficial. O výsledku se můžete přesvědčit sami, význam hodnot na ose x není potřeba dlouze rozebírat, stačí si říct, že čím více vpravo, tím více profil zapadá do daného faktoru, čím více vlevo tím se naopak tomuto faktoru vzdaluje. Dole následuje skript, který nejprve počítá faktorovou analýzu a přiřazuje hodnoty faktorů ke každému instagramovému účtu a následně vytvoří koláž z fotek a „profil“ zadaného instagramového účtu.

fa = FactorAnalysis(n_components=10, random_state=42)
trans = fa.fit_transform(df_pml_agg)
df_compos = pd.DataFrame(fa.components_, columns=df_pml_agg.columns).transpose()
compos_names = ['cars_and_motorcycles',
'posh_female',
'holiday',
'sport',
'posh_man',
'urban',
'food',
'outdoor',
'fashion',
'animal']
df_compos.columns = compos_names
df_trans = pd.DataFrame(trans, index=df_pml_agg.index, columns=compos_names)
display(df_compos.sample(5))
display(df_trans.sample(5))
img_urls = df_pm[df_pm['p_username']=='andreaveresovaofficial']['m_url'].to_list()
fig, ax = plt.subplots(nrows=1, ncols=12, figsize=(20,4))
fig.subplots_adjust(hspace=0, wspace=0)
for i, url in enumerate(img_urls):
try:
response = requests.get(url, stream=True).raw
img = np.asarray(bytearray(response.read()), dtype="uint8")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
ax[i].imshow(img)
ax[i].axis('off')
except:
ax[i].axis('off')
plt.show()
sns.barplot(x=df_trans.loc['andreaveresovaofficial'].sort_values(ascending=False), y=df_trans.loc['andreaveresovaofficial'].sort_values(ascending=False).index)
plt.show()
Vizualizace profilů
Jako pomůcku pro shrnutí a vizualizaci výsledků faktorové analýzy a tedy i takto vytvořených „obsahových profilů“ pro jednotlivé instagramové účty jsem zvolil Tableau dashboard.
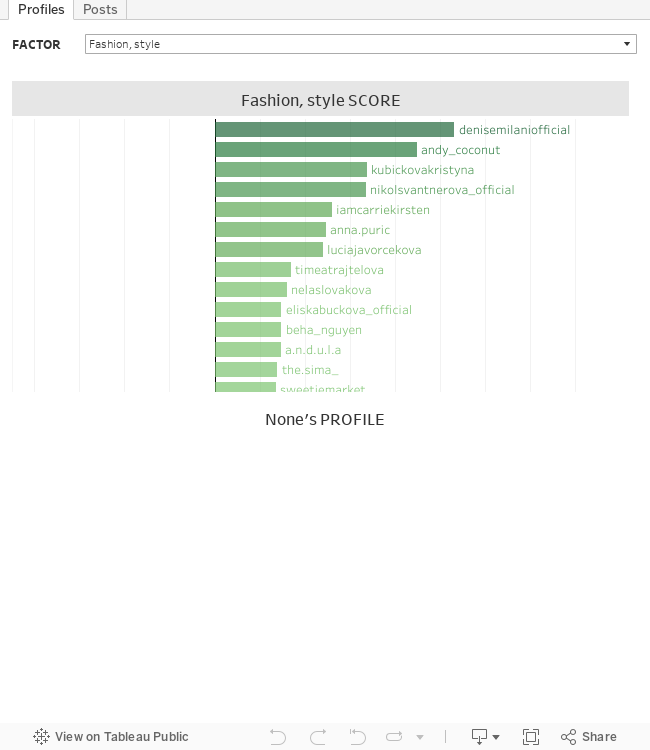
Na první záložce „Profiles“ si nahoře ve filtru pojmenovaném „FACTOR“ můžete vybrat, podle skóre kterého faktoru chcete jednotlivé insta účty seřadit (od toho, který mu odpovídá nejvíce) a po kliknutí na sloupec konkrétního účtu se v dolní části dashboardu zobrazí kompletní profil účtu z hlediska všech výše popsaných faktorů.
Druhá záložka „Posts“ se zaměřuje na jednotlivé hodnocené fotografie pro konkrétní insta účet. Ve filtru „INSTAGRAM PROFILE“ v horní části si lze vybrat konkrétní účet a po kliknutí na čísla 1 až 12, která reprezentují jednotlivé stažené fotografie z tohoto účtu (na nichž je celá analýza založena), se dole zobrazí informace o zvolené fotografii. Konkrétně její popis, který k ní autor přidal, počet likes a komentářů, jednotlivé labels, které k ní přiřadil AWS Rekognition algoritmus spolu se jejich „spolehlivostí“ (červená čára znázorňuje hodnotu 75 %, přičemž labels s nižší spolehlivostí do analýzy nevstupovaly) a konečně náhled fotografie vpravo dole.
Co s tím?
Pokud si dáte tu práci a proklikáte si několik insta účtů, jejich „obsahových profilů“ a prohlédnete si, jak AWS labely odpovídají skutečnému obsahu fotek, zjistíte dvě věci. Jednak, že i z takhle jednoduché analýzy vzešly poměrně použitelné a smysluplné výsledky a naopak, že v některých případech je hodnocení profilů přinejmenším sporné v kontextu obsahu fotek, které na něm jsou. Tohle ale rozhodně není chyba AWS ale spíše velmi jednoduché formy faktorové analýzy, se kterou jsem rozhodně nestrávil tolik času. Jak po metodické tak po interpretační stránce.
Dovedu si ale představit, že pokud by tomu někdo dostatek času věnoval, mohl by se dobrat k docela užitečnému nástroji pro výběr vhodných adeptů pro influencer marketing jednotlivých brandů nebo produktů. A nabízí se i hromada dalších potenciálních aplikací. Zvlášť pokud by se do hry zapojily i ostatní AWS Rekognition služby (já využil jen tu nejjednoduší – labeling fotek) a u každé fotky bych AWS nechal hodnotit i bezpečnost obsahu (detekuje nevhodný obsah v obrázcích a videích), detekci textu nebo rozpoznávání obličejů a emocí. Další rozměr by mohlo doplnit využití AWS Rekognition alternativy od Google – Vision AI. Tato služba oproti Amazonu nabízí navíc i možnost detekce log značek a i konkrétních produktů z dodaného produktového katalogu apod.