
Google Ngram Viewer je další z řady, neprávem prakticky neznámých, Googlích produktů, který sice již existuje několik let, ale dosud si nezískal tolik pozornosti, kolik by si pravděpodobně zasloužil. Po zadání vámi zvolené fráze vám ukáže, jak často se tato fráze vyskytuje v knihách publikovaných od roku 1800 dále (případně i starších). Samozřejmě se tím myslí, v knihách evidovaných v rámci Google Books databáze. Můžete si navíc zvolit vůči jakému korpusu budete frázi porovnávat. Těch je sice na výběr celá řada, ale česká báze knih v nich nepřekvapivě chybí. I tak je ale možné si s tímto produktem Google Research týmu docela hezky vyhrát a získat z něj pár zajímavých informací. Důležité je ale neplést si slova zajímavý a reálně využitelný, ačkoliv na konci zkusím pár aplikací do reálného prostředí navrhnout.
Lay thine eyes upon…
Například se můžete podívat na klesající oblíbenost archaické anglické fráze thou shalt. Abych náhodou nebyl nařčen ze znalosti anglických anachronismů, rovnou říkám, že je to jediná fráze, která mi zněla dost staře na to, aby se na jejím příkladě dal Ngram předvést, a znám ji jen díky tomuhle memu.
Po najetí na konkrétní bod křivky vidíte, kolik procent všech 2-grams (dvouslovných sousloví) v rámci Google Books tvoří právě fráze thou shalt. Zatímco období největší popularity si odbyla přibližně v polovině devatenáctého století, kdy tvořila asi jednu tisícinu procenta všech dvouslovných kombinací v rámci anglického korpusu, v roce 2000 se objevila již jen v asi 0,00009 % z nich.
Protože mívám sklony k tomu být infantilní, a také proto, že už jsem to slíbil v nadpisu, jsem se zkusil podívat na to, jak se vyvíjí zastoupení poměrně běžného anglického slova fuck v anglické literatuře. Čistě pro zajímavost jsem pro srovnání přidal i poněkud slušnější frázi have sex. Samozřejmě je mi jasné, že slovo fuck má mnohonásobně více významů a možných variant použití, takže toto porovnání není úplně fér.
Jak se zdá, přibližně od roku 1960, začala být anglicky psaná literatura daleko zajímavější, než do té doby… Možná se ptáte, co znamená ten peak slova fuck na začátku devatenáctého století. Když se přes odkazy pod grafem prokliknete na seznam knih, které inkriminovanou frázi obsahují, dostanete neuvěřitelně komplexní seznam literatury o zemědělství z let 1800 – 1820, ve kterých si dokonce můžete konkrétní výskyt slova dohledat. Něco mi ovšem napovídá, že za prudce vzrůstající oblibou tohoto slova od roku 1960 nestojí právě zájem o zemědělství…
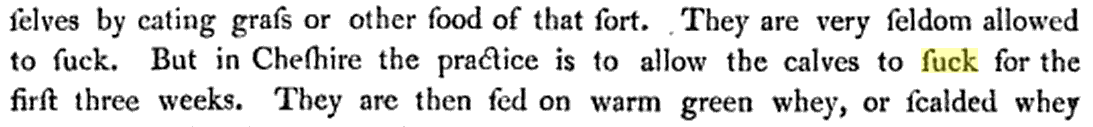
Pravděpodobně vás také zaujme velice nízký výskyt slova v období let 1820 – 1940. Ten je zřejmě způsoben podobností písmen s a f v knihách z této doby, která zřejmě mate algoritmus použitý Googlem pro rozpoznávání znaků v knihách. Velmi dobře je to sepsáno v článku Pitfalls of Using Google Ngram to Study Language.
Wildcard search
Pokud jste viděli film Boondock Saints pravděpodobně máte představu o tom, jak rozmanité může využití slova fuck být. Pokud jste film neviděli, můžete si tu zásadní scénu pustit na YouTube. Google Ngram nabízí možnost vyhledat i nejtypičtější sousloví, které je založeno na vstupní frázi. Docílíte toho přidáním * za zadané slovo.
Další možností je nechat si vyhledat různé tvary zadaného slova prostřednictvím doplnění přípony _INF. Všechny další možnosti pokročilého vyhledávání, která zahrnují například vyhledání konkrétního slovního druhu nebo porovnání výskytu fráze v různých korpusech, jsou popsané v advanced search sekci.
What the fuck?
Správná otázka, která se nabízí zní – k čemu to vlastně je? Pokud si tedy jen nechcete rozšířit svůj rozhled v oblasti cizojazyčných nadávek nebo se pokusit článkem o tomto nástroji přitáhnout někoho na svůj blog. Z mého pohledu najde tento nástroj využití hlavně mezi lingvisty a historiky, viz například práce Using Google Ngram Viewer for Scientific Referencing and History of Science. Své uplatnění by ale při troše fantazie mohl najít i v oblasti médií a marketingu, například při studiu toho, jak se vyvíjela oblíbenost různých (v té době nových) trendů , výrazů, či osob. Pokud by někoho napadl konkrétní způsob využití v nějaké oblasti, budu velice vděčný, když se o něj podělí v komentářích. Pro ty, kdo by se chtěli do zkoumání ngrams komplet datasetu ponořit hlouběji, ještě uvádím odkaz na stažení , nad kterým je Viewer postaven a také odkaz na google-ngram-downloader pro Python, který je ke stažení v rámci PyPi.